Posted September 10th, 2023
Jump to…
Dataset Background
Looking through the internet, I stumbled upon this Github repo, containing four files that were relevant to my interests for this next project. According to the Github page, “match records contain shot-by-shot data for every point of a match, including the type of shot, direction of shot, depth of returns, types of errors, and more.” Together, these four files contain almost 1,000,000 records of “raw, user-submitted, point-by-point data for pro tennis matches.” Relevant features present in the original dataset include:
- match_id (string: contains date and player names)
- Gm1, Gm2 (int: game score in the set for players 1 and 2)
- Pts (string: point score in the game ie. 0-15, 40-30, 40-AD)
- Svr (binary: whether player 1 or 2 is the server)
- 1st, 2nd (string: shot breakdown of point started by 1st and/or 2nd serves)
- isSvrWinner(binary: whether the server won the point or not)
- rallyCount(int: number of shots hit in rally)
Thank you to JeffSackmann for starting and managing this match charting project since 2013.
Python Overview (Jupyter Notebook)
I wanted to keep my code as organized as possible, so I used several user-defined functions that take one row as an input to manipulate and process the dataset. First, I wanted fields that would indicate who the “Server” and “Returner” for each point was. The functions to generate these two values isolated the player names from “match_id” and used the value of “Svr” to decide which to pick for the “Server” and “Returner” fields. Next, I wanted to know whether the point was played in the deuce or ad court. The function to generate this value used “Pts” to check for point situations that would be played in the deuce court.
One thing to keep in mind is that not all tennis points are created equal. Some are worth more than others, and therefore put more pressure on the players. Using personal experience, I defined several high-pressure situations. I defined a fourth function that would identify points that were played in these high-pressure situations. I also defined a function that would isolate the date recorded in “match_id.”
The “1st” and “2nd” fields in the original dataset contained strings of characters that encoded a shot-by-shot breakdown of the entire point. Using the character key provided with the dataset and shown below, I created regular expression patterns that could identify a variety of shots and outcomes. I then used these regular expression patterns in four functions. The first two determined the direction (wide, body, T, not served) of the 1st and 2nd serve. The last two determined the outcome of the 1st and 2nd serve (missed, not served, ace, winner, (un)forced error). The “Not Served” option was assigned only to the 2nd serve field if the 1st serve was made by the player.
| Character | Interpretation |
| 4 | wide serve (towards doubles alley) |
| 5 | body serve (middle of service box) |
| 6 | T serve (towards center line of court) |
| + | approach shot/serve and volley |
| d | deep miss |
| w | wide miss |
| x | deep and wide miss |
| n | net miss |
| f | forehand |
| b | backhand |
| r | forehand slice |
| s | backhand slice |
| * | serve ace/rally winner |
| # | serve unreturned/rally forced error |
| @ | unforced error |
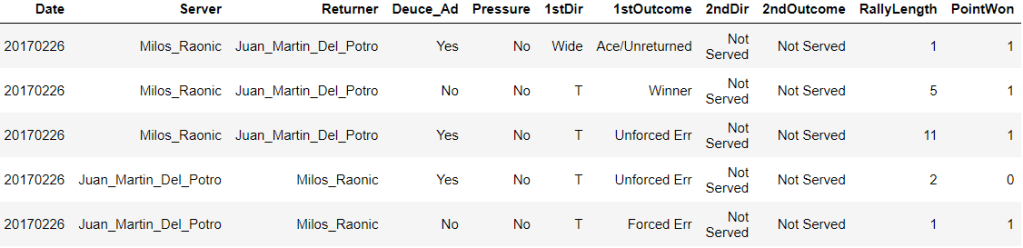
With all the helper functions defined, I read the data from the four files into pandas DataFrames. These DataFrames were processed by the helper functions to create new fields and ultimately, a new DataFrame. The first few rows of the final DataFrame are below.
Dashboard Preview (interactive view)

Analysis
Winning a service game is much easier on the pro tour than winning a return game. Therefore, gaining an advantage on the return is crucial to success. I want to highlight how players can use this dashboard to inform their serve and return strategy. This weekend at the US Open, Daniil Medvedev will play Novak Djokovic in the Men’s Finals, and Coco Gauff will play Aryna Sabalenka in the Women’s Finals. For this analysis, I used data from when Djokovic and Medvedev last played. For Gauff and Sabalenka, the dataset did not contain their previous meetings, so I used their data against all other opponents.
Coco Gauff v Aryna Sabalenka (Women’s Singles Final)
If I’m Sabalenka and I’m returning in the deuce court, I better have my forehand grip ready. When serving in the deuce court, Gauff has served out wide almost double the amount she has served up the T and into the body. Sabalenka shouldn’t lean out wide too often, however. In pressure situations, especially in the ad court where the majority of break points are faced, Gauff tends to prefer the T serve.
Sabalenka wins about 80% of forced errors when serving out wide. This is likely due to her shot after the return going to the opposite side of the court from where the returner hits the serve. Gauff should make note, and perhaps commit to the open court sooner during crucial moments when Sabalenka serves out wide. Generally, Sabalenka prefers serving out wide, especially in the ad court where the majority of break points are faced.
Daniil Medvedev v Novak Djokovic (Men’s Singles Final)
Djokovic can rest assured that he will not be jammed up by a body serve. Medvedev, when playing Djokovic, has served hundreds of times up the T and out wide, but has served into the body less than 20 times. Additionally, Medvedev’s winning percentages drop the longer the rally goes on. If Djokovic can keep some balls in play, even when on the defensive, he increases his chance of winning the point.
Medvedev could afford to serve up the T more often, especially during high-pressure situations. When serving up the T to Djokovic, Medvedev won 73% of the points, while only winning 67% when serving out wide to Djokovic. On the return, Medvedev can expect wide serves in the ad court when facing low-pressure situations. Djokovic serves out wide almost twice as much versus up the T in that scenario. Further, in the deuce court in high-pressure situations, Djokovic serves out wide about twice as much as he serves up the T.
